
About Me
Hi, this is Zerong Zheng (郑泽荣). I am currently a research scientist at Bytedance-Seed, working on multi-modal video generation.
I obtained my PhD degree from Department of Automation,
Tsinghua University. My adviser was Prof. Yebin
Liu. My research focuses on computer vision and graphics, especially 3D human
reconstruction, avatar modeling, neural human rendering, human video generation and so on.
I am one of the core contributors of OmniHuman model series (1.0 -> 1.1 -> 1.5 -> ...).
I was ranked world's top 2% scientist by Elsevier and Stanford.
Experience
Bytedance
I am currently a research scientist at Bytedance-Seed. I aim to develop the most powerful video generation & virtual human technologies, enabling users to create realistic and interactive humans-centric videos.
NNKosmos Technology
NNKosmos is a start-up founded by Prof. Yebin Liu, focusing on virtual human technologies and their application in E-commerce, entertainment and so on. As the chief algorithm scientist, I leaded the algorithm development in this company.
Facebook (Now Meta)
I was excited to join Facebook Reality Lab @ Sausalito as a research intern this summer, working with Dr. Tony Tung.
Tsinghua University
I obtained my PhD degree in June 2023, and my advisor was Prof. Yebin Liu. Before that, I received a B.Eng degree from Department of Automation, Tsinghua University in July 2018.
Research

Seedance 2.0: Advancing Video Generation for World Complexity
Seedance 2.0 adopts a unified multimodal audio-video joint generation architecture that supports text, image, audio, and video inputs, leading to the most comprehensive multimodal content reference and editing capabilities in the industry. It achieves a higher usability rate for complex interaction and motion scenes, with significant improvements in physical accuracy, visual realism, and controllability.

OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
We propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive. Inspired by the mind's "System 1 and System 2" cognitive theory, our architecture bridges a Multimodal Large Language Model and a Diffusion Transformer.

DreamVVT: Mastering Realistic Video Virtual Try-On in the Wild via a Stage-Wise Diffusion Transformer Framework
We present a stagewise framework based on Diffusion Transformers (DiTs) that effectively leverages unpaired human-centric data, pretrained model priors, and test-time inputs to achieve multi-modal-guided, highly realistic virtual try-on video generation.

DreamActor-H1: High-Fidelity Human-Product Demonstration Video Generation via Motion-designed Diffusion Transformers
We present a diffusion transformer-based framework that addresses the challenges of generating high-fidelity human-product demonstration videos by integrating masked cross-attention, 3D motion guidance, and semantic-aware text encoding.

AlignHuman: Improving Motion and Fidelity via Timestep-Segment Preference Optimization for Audio-Driven Human Animation
We propose a framework that combines Preference Optimization as a post-training technique with a divide-and-conquer training strategy to jointly optimize motion naturalness and visual fidelity of current human animation models.

InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
In this work, we discard the single-entity assumption and introduce a novel framework that enforces strong, region-specific binding of conditions from modalities to each identity's spatiotemporal footprint, enabling the high-quality generation of controllable multi-concept human-centric videos.

OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
We propose an end-to-end multimodality-conditioned human video generation framework named OmniHuman, which can generate human videos based on a single human image and motion signals (e.g., audio only, video only, or a combination of audio and video).
NOTE: We do not offer services/downloads anywhere, nor do we have any SNS accounts for the project. Please be cautious of fraudulent information.

Human4DiT: 360-degree Human Video Generation with 4D Diffusion Transformer
We present a novel framework based on 4D diffusion transformer, which adopts a cascaded structure consisting of the 2D image, the view transformer, and the temporal blocks. Given a reference image, SMPL sequences and camera parameters, our method is capable of generating free-view dynamic human videos.
MeshAvatar: Learning High-quality Triangular Human Avatars from Multi-view Videos
We present a novel pipeline for learning high-quality triangular human avatars from multi-view videos. Our method represents the avatar with an explicit triangular mesh extracted from an implicit SDF field, complemented by an implicit material field conditioned on given poses.
@inproceedings{chen2024meshavatar,
title={MeshAvatar: Learning High-quality Triangular Human Avatars from Multi-view Videos},
author={Yushuo Chen and Zerong Zheng and Zhe Li and Chao Xu and Yebin Liu},
booktitle={ECCV},
year={2024}
}

3D Gaussian Parametric Head Model
We introduce 3D Gaussian Parametric Head Model (GPHM), which employs 3D Gaussians to accurately represent the complexities of the human head, allowing precise control over both identity and expression..
@inproceedings{xu2023gphm,
title={3D Gaussian Parametric Head Model},
author={Xu, Yuelang and Wang, Lizhen and Zheng, Zerong and Su, Zhaoqi and Liu, Yebin},
booktitle={ECCV},
year={2024}
}

LayGA: Layered Gaussian Avatars for Animatable Clothing Transfer
We present Layered Gaussian Avatars (LayGA), a new representation that formulates body and clothing as two separate layers for photorealistic animatable clothing transfer from multiview videos.
@inproceedings{lin2024layga,
title={LayGA: Layered Gaussian Avatars for Animatable Clothing Transfer},
author={Lin, Siyou and Li, Zhe and Su, Zhaoqi and Zheng, Zerong and Zhang, Hongwen and Liu, Yebin},
booktitle={SIGGRAPH Conference Papers},
year={2024}
}

Animatable Gaussians: Learning Pose-dependent Gaussian Maps for High-fidelity Human Avatar Modeling
We introduce Animatable Gaussians, a new avatar representation that leverages powerful 2D CNNs and 3D Gaussian splatting to create high-fidelity avatars.
@inproceedings{li2023animatablegaussians,
title={Animatable Gaussians: Learning Pose-dependent Gaussian Maps for High-fidelity Human Avatar Modeling},
author={Li, Zhe and Zheng, Zerong and Wang, Lizhen and Liu, Yebin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
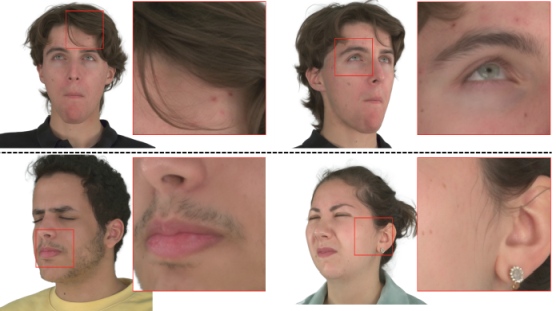
Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians
We propose Gaussian Head Avatar represented by controllable 3D Gaussians for high-fidelity head avatar modeling. Our approach can achieve ultra high-fidelity rendering quality at 2K resolution even under exaggerated expressions.
@inproceedings{xu2023gaussianheadavatar,
title={Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians},
author={Xu, Yuelang and Chen, Benwang and Li, Zhe and Zhang, Hongwen and Wang, Lizhen and Zheng, Zerong and Liu, Yebin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}

DiffPerformer: Iterative Learning of Consistent Latent Guidance for Diffusion-based Human Video Generation
We propose a novel framework, DiffPerformer, to synthe006 size high-fidelity and temporally consistent human video using the prior in a pre-trained diffusion model.

Control4D: Efficient 4D Portrait Editing with Text
We introduce Control4D, an innovative framework for editing dynamic 4D portraits using text instructions. Our method consists of GaussianPlanes, a novel 4D representation that applies plane-based decomposition to Gaussian Splatting, and a 4D generator to learn a more continuous generation space .
@inproceedings{shao2023control4d,
title = {Control4D: Efficient 4D Portrait Editing with Text},
author = {Shao, Ruizhi and Sun, Jingxiang and Peng, Cheng and Zheng, Zerong and Zhou, Boyao and Zhang, Hongwen and Liu, Yebin},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year = {2024}
}
RAM-Avatar: Real-time Photo-Realistic Avatar from Monocular Videos with Full-body Control
We propose a new method for learning real-time, photo-realistic avatars in the 2D image domain that support full-body control from monocular videos.

Leveraging Intrinsic Properties for Non-Rigid Garment Alignment
We address the problem of aligning real-world 3D data of garments by proposing a novel coarse-to-fine two-stage method that leverages intrinsic manifold properties with two neural deformation fields, in the 3D space and the intrinsic space, respectively.
@inproceedings{lin2023intgam,
author={Siyou Lin and Boyao Zhou and Zerong Zheng and Hongwen Zhang and Yebin Liu},
title={Leveraging Intrinsic Properties for Non-Rigid Garment Alignment},
booktitle = {ICCV},
year = {2023}
}
AvatarReX: Real-time Expressive Full-body Avatars
We present AvatarReX, a new method for learning NeRF-based full-body avatars from video data. The learnt avatar not only provides expressive control of the body, hands and the face together, but also supports real-time animation and rendering.
@article{zheng2023avatarrex,
author={Zheng, Zerong and Zhao, Xiaochen and Zhang, Hongwen and Liu, Boning and Liu, Yebin},
title={AvatarRex: Real-time Expressive Full-body Avatars},
journal={ACM Transactions on Graphics (TOG)},
volume={42},
number={4},
articleno={},
year={2023}
}

PoseVocab: Learning Joint-structured Pose Embeddings for Human Avatar Modeling
we present PoseVocab, a novel pose encoding method that encourages the network to encode the dynamic details of human appearance into multiple structural levels, enabling realistic and generalized animation under novel poses.
@article{li2023posevocab,
author={Li, Zhe and Zheng, Zerong and Liu, Yuxiao and Zhou, Boyao and Liu, Yebin},
title={PoseVocab: Learning Joint-structured Pose Embeddings for Human Avatar Modeling},
journal={ACM SIGGRAPH Conference Proceedings},
year={2023}
}

Tensor4D : Efficient Neural 4D Decomposition for High-fidelity Dynamic Reconstruction and Rendering
We present Tensor4D, an efficient yet effective approach to dynamic scene modeling. The key of our solution is an efficient 4D tensor decomposition method where the dynamic scene is directly represented as a 4D spatio-temporal tensor.
@inproceedings{shao2023tensor4d,
author = {Shao, Ruizhi and Zheng, Zerong and Tu, Hanzhang and Liu, Boning and Zhang, Hongwen and Liu, Yebin},
title = {Tensor4D: Efficient Neural 4D Decomposition for High-fidelity Dynamic Reconstruction and Rendering},
booktitle = {CVPR},
year = {2023}
}
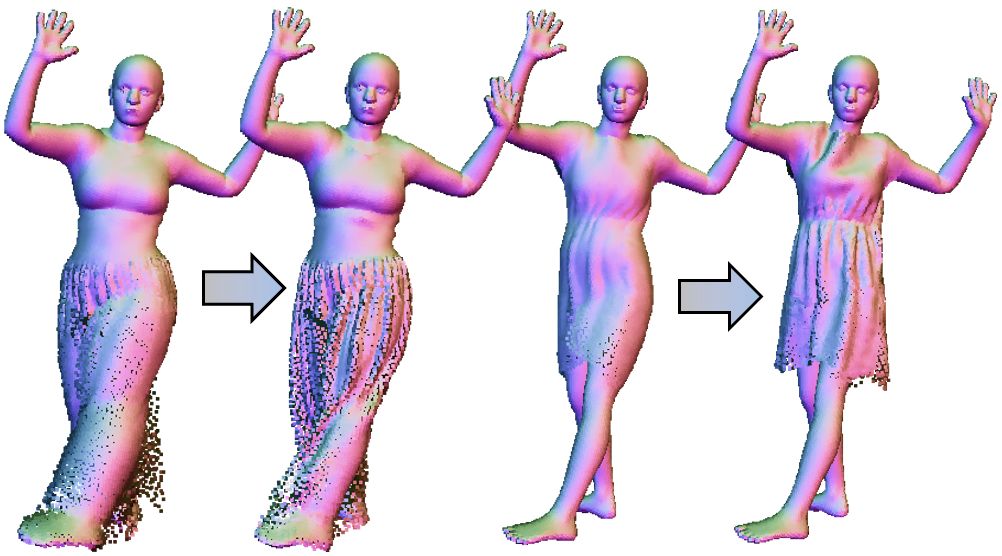
CloSET: Modeling Clothed Humans on Continuous Surface with Explicit Template Decomposition
We propose a point-based method that can decompose garment-related templates and then add pose-dependent wrinkles upon them. In this way, the clothing deformations are disentangled such that the pose-dependent wrinkles can be better learned and applied to unseen poses.
@inproceedings{zhang2023closet,
author = {Zhang, Hongwen and Lin, Siyou and Shao, Ruizhi and Zhang, Yuxiang and Zheng, Zerong and Huang, Han and Guo, Yandong and Liu, Yebin},
title = {CloSET: Modeling Clothed Humans on Continuous Surface with Explicit Template Decomposition},
booktitle = {CVPR},
year = {2023}
}

FloRen: Real-time High-quality Human Performance Rendering via Appearance Flow Using Sparse RGB Cameras
We propose FloRen, a novel system for real-time, high-resolution free-view human synthesis. Our system runs at 15fps in 1K resolution with very sparse RGB cameras.
@inproceedings{shao2022floren,
author = {Shao, Ruizhi and Chen, Liliang and Zheng, Zerong and Zhang, Hongwen and Zhang, Yuxiang and Huang, Han and Guo, Yandong and Liu, Yebin},
title = {FloRen: Real-Time High-Quality Human Performance Rendering via Appearance Flow Using Sparse RGB Cameras},
booktitle = {SIGGRAPH Asia 2022 Conference Papers},
year = {2022}
}

DiffuStereo: High Quality Human Reconstruction via Diffusion-based Stereo Using Sparse Cameras
We propose DiffuStereo, a novel system using only sparse cameras for high-quality 3D human reconstruction. At its core is a novel diffusion-based stereo module, which introduces diffusion models into the iterative stereo matching framework.
@inproceedings{shao2022diffustereo,
author = {Shao, Ruizhi and Zheng, Zerong and Zhang, Hongwen and Sun, Jingxiang and Liu, Yebin},
title = {DiffuStereo: High Quality Human Reconstruction via Diffusion-based Stereo Using Sparse Cameras},
booktitle = {ECCV},
year = {2022}
}
AvatarCap: Animatable Avatar Conditioned Monocular Human Volumetric Capture
AvatarCap is a novel framework that introduces animatable avatars into the capture pipeline for high-fidelity volumetric capture from monocular RGB inputs. It can reconstruct the dynamic details in both visible and invisible regions.
@InProceedings{li2022avatarcap,
title={AvatarCap: Animatable Avatar Conditioned Monocular Human Volumetric Capture},
author={Li, Zhe and Zheng, Zerong and Zhang, Hongwen and Ji, Chaonan and Liu, Yebin},
booktitle={European Conference on Computer Vision (ECCV)},
month={October},
year={2022},
}
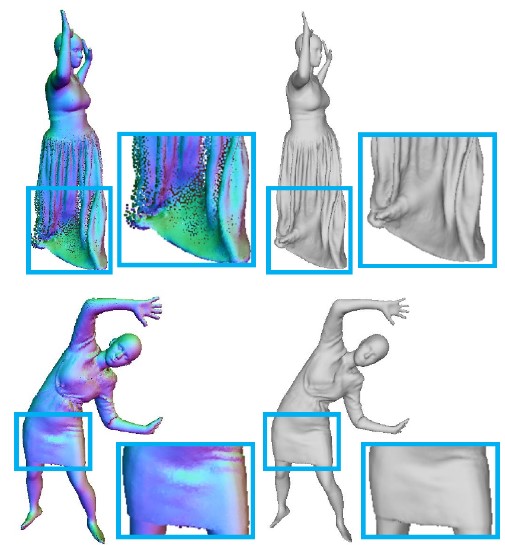
Learning Implicit Templates for Point-Based Clothed Human Modeling
We present FITE, a First-Implicit-Then-Explicit framework for modeling human avatars in clothing. Our framework first learns implicit surface templates representing the coarse clothing topology, and then employs the templates to guide the generation of point sets which further capture pose-dependent clothing deformations such as wrinkles.
@inproceedings{lin2022fite,
title={Learning Implicit Templates for Point-Based Clothed Human Modeling},
author={Lin, Siyou and Zhang, Hongwen and Zheng, Zerong and Shao, Ruizhi and Liu, Yebin},
booktitle={ECCV},
year={2022}
}

Structured Local Radiance Fields for Human Avatar Modeling
We introduce a novel representation for learning animatable full-body avatars in general clothes without any pre-scanning efforts. The core of our representation is a set of structured local radiance fields, which makes no assumption about the cloth topology but is still able to model the cloth motions in a coarse-to-fine manner.
@InProceedings{zheng2022structured,
title={Structured Local Radiance Fields for Human Avatar Modeling},
author={Zheng, Zerong and Huang, Han and Yu, Tao and Zhang, Hongwen and Guo, Yandong and Liu, Yebin},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {}
}
High-Fidelity Human Avatars from a Single RGB Camera
We propose a new framework to reconstruct a personalized high-fidelity human avatar from a monocualr video. Our method is able to recover the pose-dependent surface deformations as well as high-quality appearance details.
@InProceedings{zhao2022highfidelity,
title={High-Fidelity Human Avatars from a Single RGB Camera},
author={Zhao, Hao and Zhang, Jinsong and Lai, Yu-Kun and Zheng, Zerong and Xie, Yingdi and Liu, Yebin and Li, Kun},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {}
}
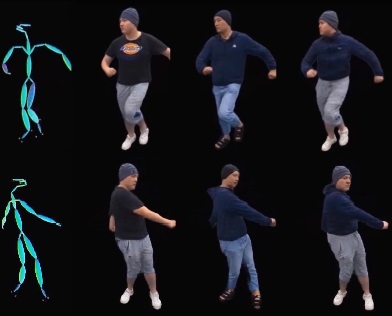
HVTR: Hybrid Volumetric-Textural Rendering for Human Avatars
We propose a novel neural rendering pipeline, Hybrid Volumetric-Textural Rendering (HVTR), which synthesizes virtual human avatars from arbitrary poses efficiently and at high quality by combining 2D UV-based latent features with 3D volumetric representation.
@article{hu2021hvtr,
title={HVTR: Hybrid Volumetric-Textural Rendering for Human Avatars},
author={Tao Hu and Tao Yu and Zerong Zheng and He Zhang and Yebin Liu and Matthias Zwicker},
eprint={2112.10203},
archivePrefix={arXiv},
year = {2022},
primaryClass={cs.CV}
}
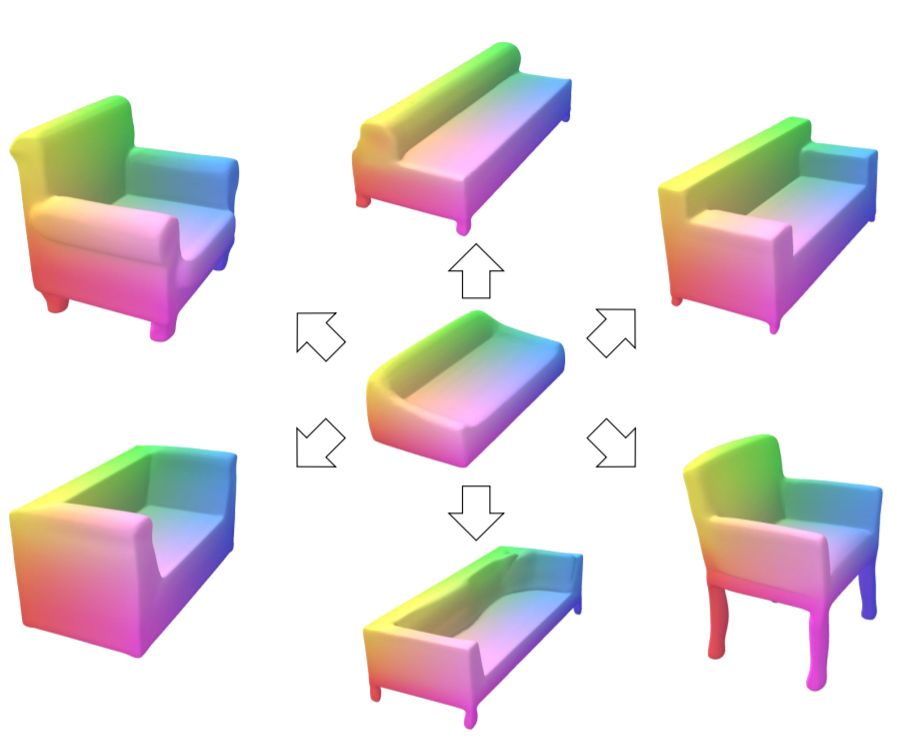
Deep Implicit Templates for 3D Shape Representation
We propose Deep Implicit Templates, a new 3D shape representation that supports explicit mesh correspondence reasoning in deep implicit representations. Our key idea is to formulate deep implicit functions as conditional deformations of a template implicit function.
@InProceedings{zheng2021dit,
author = {Zheng, Zerong and Yu, Tao and Dai, Qionghai and Liu, Yebin},
title = {Deep Implicit Templates for 3D Shape Representation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {1429-1439}
}

Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
We propose a human volumetric capture method that combines temporal volumetric fusion and deep implicit functions. Our method outperforms existing methods in terms of view sparsity, generalization capacity, reconstruction quality, and run-time efficiency.
@InProceedings{yu2021function4d,
author = {Yu, Tao and Zheng, Zerong and Guo, Kaiwen and Liu, Pengpeng and Dai, Qionghai and Liu, Yebin},
title = {Function4D: Real-Time Human Volumetric Capture From Very Sparse Consumer RGBD Sensors},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {5746-5756}
}

POSEFusion:Pose-guided Selective Fusion for Single-view Human Volumetric Capture
We propose POse-guided SElective Fusion (POSEFusion), a single-view human volumetric capture method that leverages tracking-based methods and tracking-free inference to achieve high-fidelity and dynamic 3D reconstruction.
@InProceedings{li2021posefusion,
author = {Li, Zhe and Yu, Tao and Zheng, Zerong and Guo, Kaiwen and Liu, Yebin},
title = {POSEFusion: Pose-Guided Selective Fusion for Single-View Human Volumetric Capture},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {14162-14172}
}

DeepMultiCap: Performance Capture of Multiple Characters Using Sparse Multiview Cameras
We propose DeepMultiCap, a novel method for multi-person performance capture using sparse multi-view cameras. Our method can capture time varying surface details without the need of using pre-scanned template models.
@misc{shao2021dmc,
title={DeepMultiCap: Performance Capture of Multiple Characters Using Sparse Multiview Cameras},
author={Yang Zheng and Ruizhi Shao and Yuxiang Zhang and Zerong Zheng and Tao Yu and Yebin Liu},
booktitle={IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
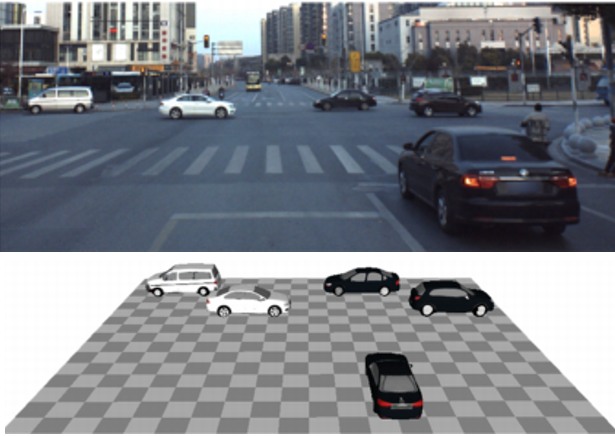
VERTEX: VEhicle Reconstruction and TEXture Estimation Using Deep Implicit Semantic Template Mapping
We introduce VERTEX, an effective solution to recover 3D shape and intrinsic texture of vehicles from uncalibrated monocular input in real-world street environments.
@article{zhao2020vertex,
title={VERTEX: VEhicle Reconstruction and TEXture Estimation Using Deep Implicit Semantic Template Mapping},
author={Xiaochen Zhao, Zerong Zheng, Chaonan Ji, Zhenyi Liu, Yirui Luo, Tao Yu, Jinli Suo, Qionghai Dai, Yebin Liu},
year={2020},
eprint={2011.14642},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
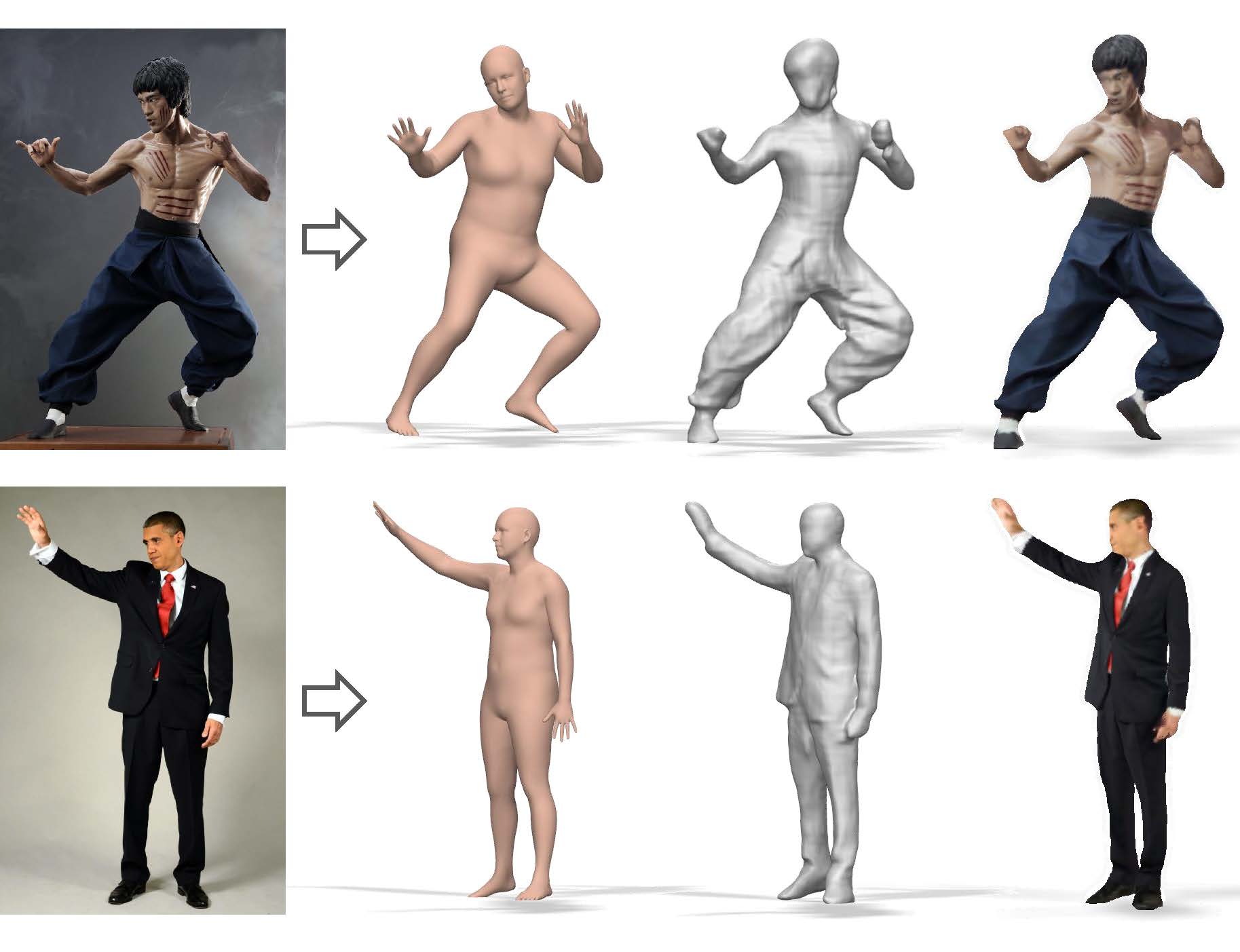
PaMIR: Parametric Model-Conditioned Implicit Representation for Image-based Human Reconstruction
We propose Parametric Model-Conditioned Implicit Representation (PaMIR), which combines the parametric body model with the free-form deep implicit functions for robust 3D human reconstruction from a single RGB image or multiple images.
@article{pamir2020,
author={Zerong Zheng and Tao Yu and Yebin Liu and Qionghai Dai},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={PaMIR: Parametric Model-Conditioned Implicit Representation for Image-based Human Reconstruction},
year={2021},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2021.3050505}
}

RobustFusion: Human Volumetric Capture with Data-driven Visual Cues using a RGBD Camera
We introduce a robust template-less human volumetric capture system combined with various data-driven visual cues, which outperforms existing state-of-the-art approaches significantly.
@InProceedings{robustfusion2020,
author={Su, Zhuo and Xu, Lan and Zheng, Zerong and Yu, Tao and Liu, Yebin and Fang, Lu},
editor={Vedaldi, Andrea and Bischof, Horst and Brox, Thomas and Frahm, Jan-Michael},
title={RobustFusion: Human Volumetric Capture with Data-Driven Visual Cues Using a RGBD Camera},
booktitle={European Conference on Computer Vision (ECCV)},
year={2020},
publisher={Springer International Publishing},
address={Cham},
pages={246--264},
isbn={978-3-030-58548-8}
}

Robust 3D Self-portraits in Seconds
We propose an efficient method for robust 3d self-portraits using a single RGBD camera. Our method can generate detailed 3D self-portraits in seconds and is able to handle challenging clothing topologies.
@InProceedings{Li2020portrait,
author = {Li, Zhe and Yu, Tao and Pan, Chuanyu and Zheng, Zerong and Liu, Yebin},
title = {Robust 3D Self-portraits in Seconds},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month={June},
year={2020},
pages={1344-1353}
}

DeepHuman: 3D Human Reconstruction from a Single Image
We propose DeepHuman, a deep learning based framework for 3D human reconstruction from a single RGB image. We also contribute THuman, a 3D real-world human model dataset containing approximately 7000 models.
@InProceedings{Zheng2019DeepHuman,
author = {Zheng, Zerong and Yu, Tao and Wei, Yixuan and Dai, Qionghai and Liu, Yebin},
title = {DeepHuman: 3D Human Reconstruction From a Single Image},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
pages={7739-7749},
year = {2019}
}

SimulCap : Single-View Human Performance Capture with Cloth Simulation
This paper proposes a new method for live free-viewpoint human performance capture with dynamic details (e.g., cloth wrinkles) using a single RGBD camera. By incorporating cloth simulation into the performance capture pipeline, we can generate plausible cloth dynamics and cloth-body interactions.
@InProceedings{Yu2019SimulCap,
author = {Yu, Tao and Zheng, Zerong and Zhong, Yuan and Zhao, Jianhui and Dai, Qionghai and Pons-Moll, Gerard and Liu, Yebin},
title = {SimulCap : Single-View Human Performance Capture With Cloth Simulation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
pages={5504-5514},
year = {2019}
}
HybridFusion: Real-time Performance Capture Using a Single Depth Sensor and Sparse IMUs
We propose a light-weight and highly robust real-time human performance capture method based on a single depth camera and sparse inertial measurement units (IMUs).
@InProceedings{Zheng2018HybridFusion,
author = {Zheng, Zerong and Yu, Tao and Li, Hao and Guo, Kaiwen and Dai, Qionghai and Fang, Lu and Liu, Yebin},
title = {HybridFusion: Real-time Performance Capture Using a Single Depth Sensor and Sparse IMUs},
booktitle = {European Conference on Computer Vision (ECCV)},
month={Sept},
year={2018},
}
DoubleFusion: Real-time Capture of Human Performances with Inner Body Shapes from a Single Depth Sensor
We propose DoubleFusion, a new real-time system that combines volumetric dynamic reconstruction with datadriven template fitting to simultaneously reconstruct detailed geometry, non-rigid motion and the inner human body shape from a single depth camera.
@inproceedings{yu2018DoubleFusion,
title = {DoubleFusion: Real-time Capture of Human Performance with Inner Body Shape from a Depth Sensor},
author = {Tao, Yu and Zheng, Zerong and Guo, Kaiwen and Zhao, Jianhui and Quionhai, Dai and Li, Hao and Pons-Moll, Gerard and Liu, Yebin},
booktitle = {{IEEE} Conference on Computer Vision and Pattern Recognition},
note = {{CVPR} Oral},
year = {2018}
}
Distinction
National Scholarship, Ministry of Education of China
Tsinghua-Hefei First Class Scholarship, Tsinghua University
Future Scholar Fellowship (×3 years), Tsinghua University
Excellent Bachelor Thesis Award, Tsinghua University
Academic Excellence Award, Tsinghua-GuangYao Scholarship, Tsinghua University
Excellence Award & Scholarship for Technological Innovation, Tsinghua University
Academic Excellence Award, Tsinghua-Hengda Scolarship, Tsinghua University
Excellence Award for Technological Innovation, Tsinghua University
Academic Excellence Award & Scholarship, Tsinghua University
Others
Skills
- C++ (OpenCV, OpenGL, CUDA, Eigen, PCL, Qt, ...)
- Python (Tensorflow/PyTorch)
- Matlab, C#
- LaTex
Languages
- Chinese (native)
- English (TOEFL: 101; GRE: 152+170+4.0)